AIOS RL 训练系统:从合成 BUG 修复到多环境联合学习¶
自推出 aios orchestrate 实时执行以来,我们在底层构建了一个更深层的东西:一个多环境强化学习系统,能在 shell、浏览器和编排器任务中持续改进学生策略——所有环境共用一个统一的训练控制平面。
这篇文章解释我们构建了什么、为什么这样构建,以及它解锁了什么能力。

单环境 RL 的问题¶
在 RL 之前,系统只有一个隐式的"学生"——存在于技能提示词、分发策略和脚线(harness)启发式规则中的行为先验。每个新功能都需要手动调优。从"演示可用"到"生产可靠"的路径很长、很手动。
做 RL 是显而易见的方向。但我们很快发现:
如果分别复制修改 shell RL、browser RL、orchestrator RL 的控制平面,最终会得到三个相似但不兼容的 RL 实现。后果是: - 回滚语义分叉 - 重放路由不可比较 - 检查点谱系变成环境专属而非系统级 - 多个不兼容的教师/裁判集成层 - 调试被"等等,为什么 browser RL 做法不一样?"主导
正确的架构是:先抽取共享控制平面,再把环境接入它。
架构:1 个核心 + 3 个环境¶
scripts/lib/rl-core/ ← 共享控制平面
├── campaign-controller.mjs ← 采集/监控 epoch 编排
├── checkpoint-registry.mjs ← active / pre_update_ref / last_stable 谱系
├── comparison-engine.mjs ← better / same / worse / comparison_failed
├── control-state-store.mjs ← 重启安全的控制快照
├── epoch-ledger.mjs ← epoch 状态 + 降级连续记录
├── replay-pool.mjs ← 四车道路由(正/中/负/诊断)
├── reward-engine.mjs ← 环境奖励 + 教师塑形融合
├── teacher-gateway.mjs ← 标准化教师输出(Codex/Claude/Gemini/opencode)
├── schema.mjs ← 所有共享契约验证
└── trainer.mjs ← PPO 入口(在线 + 离线)
scripts/lib/rl-shell-v1/ ← Shell 环境(合成 BUG 修复任务)
scripts/lib/rl-browser-v1/ ← 浏览器环境(受控真实网页流程)
scripts/lib/rl-orchestrator-v1/ ← 编排器环境(控制决策)
scripts/lib/rl-mixed-v1/ ← 混合环境训练
RL Core 拥有通用训练控制平面。它定义 episode 契约、batch 语义、对比和降级跟踪、检查点谱系、回滚规则、重放路由和训练器入口。
环境适配器 拥有所有执行相关的事:任务采样、episode 执行、证据收集和环境专属验证输入。它们实现一个薄薄的适配器接口——没有 RL 逻辑泄漏进来。
共享 Episode 契约¶
每个 episode——无论 shell、browser 还是 orchestrator——产生相同结构化的输出:
Episode {
episodeId: string;
environment: 'shell' | 'browser' | 'orchestrator';
taskId: string;
trajectory: TrajectoryStep[]; // 智能体动作 + 观察
outcome: 'success' | 'partial' | 'failure' | 'blocked';
reward: number;
teacherSignal?: TeacherSignal; // 失败 + 边界 episode 时出现
comparison?: ComparisonResult; // 与上一策略对比
}
这种统一性使得跨环境对比和重放路由有意义。
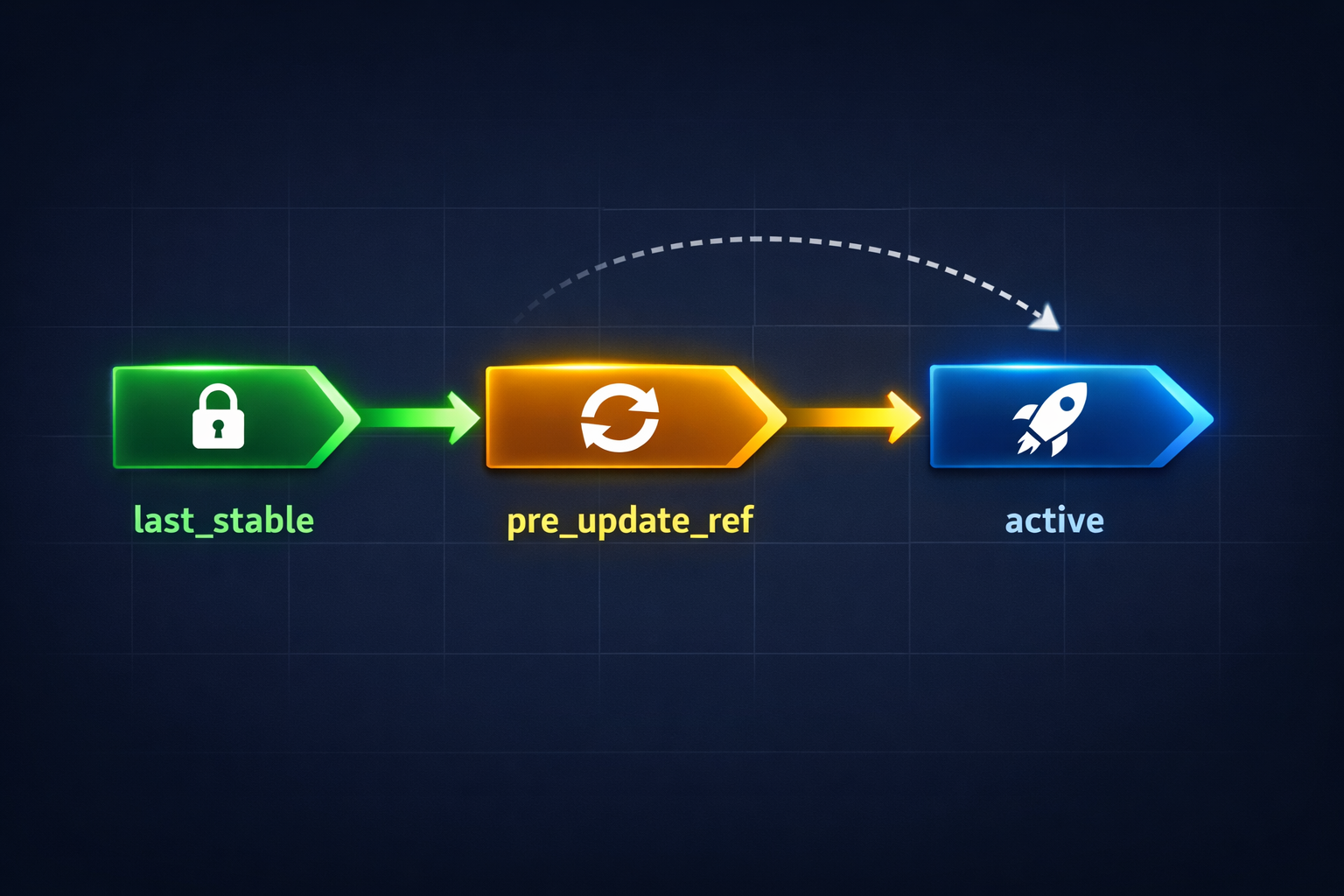
检查点谱系:三指针模型¶
active ────────────── 当前使用的策略
│
├── pre_update_ref ── 上次 PPO 更新前的快照(回滚目标)
│
└── last_stable ───── 上次经对比确认的稳定策略
- 每次 PPO 更新创建新的
active检查点。 - 应用更新前,前一个
active成为pre_update_ref。 - 如果下次对比显示降级,系统回滚到
pre_update_ref。 - 经过足够多次稳定对比后,
active被提升为last_stable。
这给了我们带自动回滚的安全探索——这是让在线学习可控的核心保证。
重放池:四个车道¶
不存储每个 episode,而是按对比结果路由到车道:
| 车道 | 条件 | 用途 |
|---|---|---|
positive |
比上一策略更好 | PPO + 蒸馏 |
neutral |
与上一策略相同 | 多样性采样 |
negative |
比上一策略更差 | KL 正则化目标 |
diagnostic_only |
教师裁判判定为边界案例 | 分析,不参与训练 |
路由是确定性的——基于对比结果,而非学习型路由器。这保持系统简单可调试。

联合环境训练¶
最强大的能力是联合环境训练(rl-mixed-v1)。一个实时 batch 可以包含 shell + browser + orchestrator episode。训练控制器:
- 按平衡比例跨环境采样任务。
- 并发运行 episodes。
- 聚合奖励和对比结果。
- 为整个学生做一个回滚决策——而非每个环境单独决策。
这意味着 shell BUG 修复和 orchestrator 分发决策都能改进同一个学生策略。共享奖励信号是"这是否有助于智能体成功完成端到端任务?"
训练阶段¶
- Phase 1 (V1):合成 shell BUG 修复任务 + 教师塑形。可复现,快速迭代。
- Phase 2:真实 shell 仓库任务。同一个学生,更难分布。
- Phase 3:在线监控 + 晋升。受回滚保护的实时更新。
- Phase B:浏览器适配器——受控真实网页流程(认证墙、表单提交、滚动模式)。
- Phase C:编排器适配器——高价值控制决策(预检门控、分发路由、质量信号)。
- Phase D/E:联合环境验证——三个环境一起验证。
这解锁了什么¶
有了跨环境的共享学生策略,我们可以:
- 改进分发路由:通过编排器决策训练——哪些任务应该给 subagent vs. dry-run vs. 人工门控?
- 减少 clarity-gate 误报:通过 blocked-checkpoint episode 训练——真正的"需要人工"信号长什么样 vs. 噪声?
- 提升浏览器自动化精度:通过网页交互模式训练——哪些点击序列可靠地完成认证、表单提交或内容创建?
- 跨环境学习迁移:shell RL 对错误恢复的改进也能帮助遇到错误的浏览器任务。
如何运行¶
# Shell RL:基准生成 → 训练 → 评估
node scripts/rl-shell-v1.mjs benchmark-generate --count 20
node scripts/rl-shell-v1.mjs train --epochs 5
node scripts/rl-shell-v1.mjs eval
# 联合环境训练
node scripts/rl-mixed-v1.mjs mixed --browser-only
node scripts/rl-mixed-v1.mjs mixed --orchestrator-only
node scripts/rl-mixed-v1.mjs mixed --mixed
# 评估联合训练
node scripts/rl-mixed-v1.mjs mixed-eval
当前状态¶
- RL Core:稳定 — 所有共享契约已验证,40+ 测试通过
- Shell RL V1:稳定 — Phase 1 + 2 已实现,Phase 3 在线监控进行中
- Browser RL V1:Beta — 适配器 + 评估线束已实现
- Orchestrator RL V1:Beta — 适配器 + 评估线束已实现
- 联合环境训练:实验性 — 在留出任务上完成了端到端验证
下一个里程碑是 Phase D/E 验证:确认联合环境训练能在所有三个环境的留出任务上产生优于单环境训练的学生。
延伸阅读¶
- AIOS 架构 — 脚线、分发器和 RL 模块布局
- RL Core 设计规范 — 完整技术规格
- 浏览器 + 编排器 RL 设计 — 联合环境详情