AIOS RL Training System: From Synthetic Bugfixes to Mixed-Environment Learning¶
Since launching aios orchestrate live execution, we've been building something deeper underneath: a multi-environment reinforcement learning system that continuously improves the student policy across shell, browser, and orchestrator tasks — all sharing one unified training control plane.
This post explains what we built, why we built it that way, and what it unlocks.

The Problem with Per-Environment RL¶
Before RL, the system had one "student" — an implicit behavioral prior that lived in skill prompts, dispatch policies, and harness heuristics. Each new capability required hand-tuning. The path from "works in demo" to "works reliably in production" was long and manual.
The obvious next step was reinforcement learning. But here's what we found quickly:
If we added shell RL, browser RL, and orchestrator RL by copying and modifying each control plane independently, we'd end up with three similar but incompatible RL implementations. That's how you get: - Diverging rollback semantics - Incomparable replay routing - Environment-specific checkpoint lineage instead of system-wide - Multiple teacher/judge integration layers that don't compose - Debugging sessions dominated by "wait, why does browser RL do it differently?"
The right architecture was to extract the shared control plane first, then plug environments into it.
Architecture: One Core, Three Environments¶
scripts/lib/rl-core/ <- Shared control plane
├── campaign-controller.mjs <- collection/monitoring epoch orchestration
├── checkpoint-registry.mjs <- active / pre_update_ref / last_stable lineage
├── comparison-engine.mjs <- better / same / worse / comparison_failed
├── control-state-store.mjs <- restart-safe control snapshots
├── epoch-ledger.mjs <- epoch state + degradation streaks
├── replay-pool.mjs <- four-lane routing (positive/neutral/negative/diagnostic)
├── reward-engine.mjs <- environment reward + teacher shaping fusion
├── teacher-gateway.mjs <- normalized teacher outputs (Codex/Claude/Gemini/opencode)
├── schema.mjs <- all shared contracts validated here
└── trainer.mjs <- PPO entry points (online + offline)
scripts/lib/rl-shell-v1/ <- Shell environment (synthetic bugfix tasks)
scripts/lib/rl-browser-v1/ <- Browser environment (controlled real web flows)
scripts/lib/rl-orchestrator-v1/ <- Orchestrator environment (control decisions)
scripts/lib/rl-mixed-v1/ <- Mixed-environment campaigns
RL Core owns the common training control plane. It defines the episode contract, batch semantics, comparison and degradation tracking, checkpoint lineage, rollback rules, replay routing, and trainer entry points.
Environment adapters own everything execution-specific: task sampling, episode execution, evidence collection, and environment-specific verification inputs. They implement a thin adapter interface — no RL logic leaks in.
The Shared Episode Contract¶
Every episode — whether shell, browser, or orchestrator — produces the same structured output:
Episode {
episodeId: string;
environment: 'shell' | 'browser' | 'orchestrator';
taskId: string;
trajectory: TrajectoryStep[]; // agent actions + observations
outcome: 'success' | 'partial' | 'failure' | 'blocked';
reward: number;
teacherSignal?: TeacherSignal; // present on failures + boundary episodes
comparison?: ComparisonResult; // vs. previous policy
}
This uniformity is what makes cross-environment comparison and replay routing meaningful.
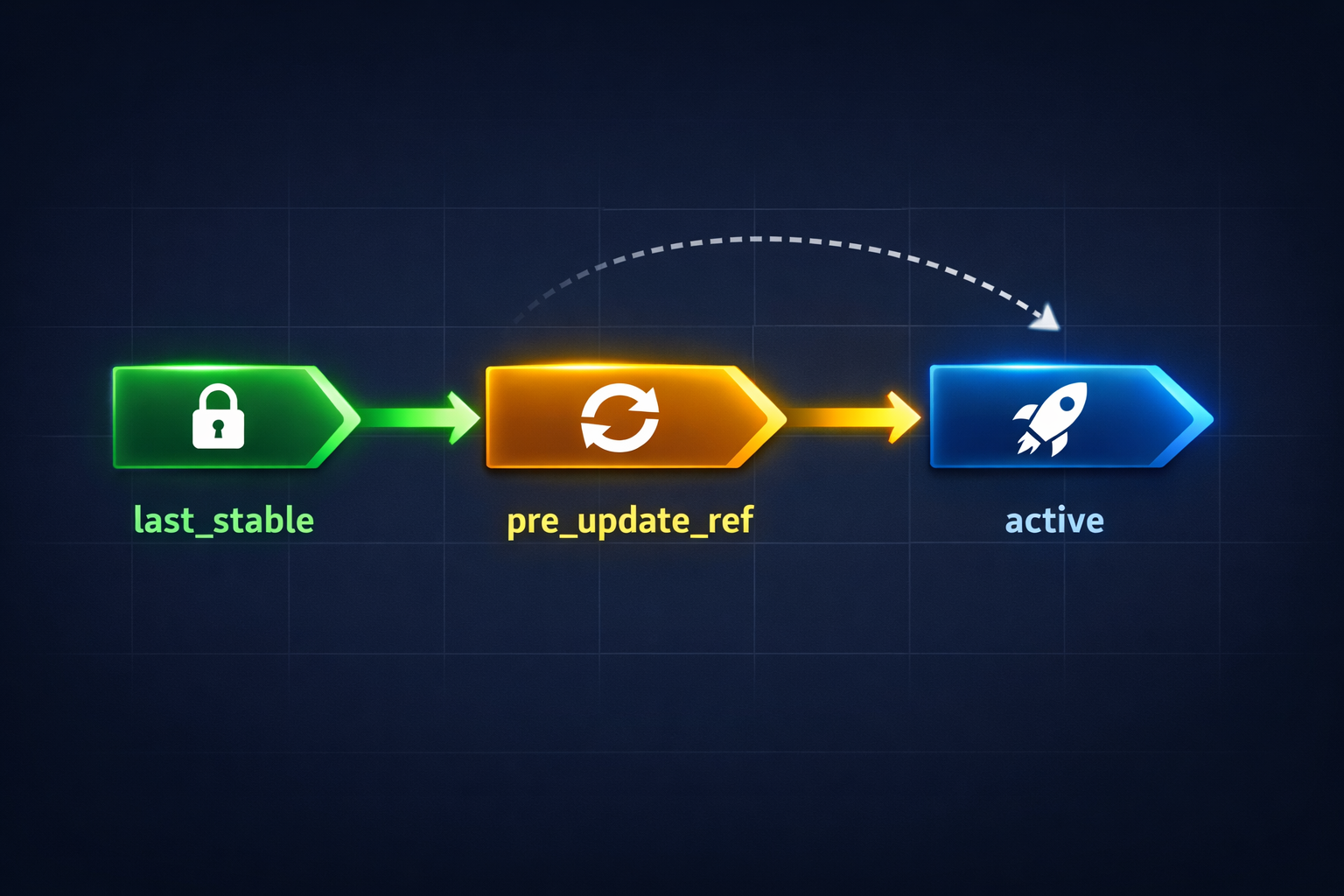
Checkpoint Lineage: Three-Pointer Model¶
active ────────────── current policy in use
│
├── pre_update_ref ── snapshot before last PPO update (rollback target)
│
└── last_stable ───── last comparison-confirmed stable policy
- Every PPO update creates a new
activecheckpoint. - Before applying the update, the previous
activebecomespre_update_ref. - If the next comparison shows degradation, the system rolls back to
pre_update_ref. - After enough stable comparisons,
activeis promoted tolast_stable.
This gives us safe exploration with automatic rollback — the core guarantee that makes online learning tractable.
Replay Pool: Four Lanes¶
Instead of storing every episode, we route them into lanes by comparison outcome:
| Lane | Criteria | Usage |
|---|---|---|
positive |
better than previous policy | PPO + distillation |
neutral |
same as previous policy | diversity sampling |
negative |
worse than previous | KL regularization target |
diagnostic_only |
teacher-judged boundary cases | analysis, not training |
The routing is deterministic — based on comparison result, not a learned router. This keeps the system simple and debuggable.

Mixed-Environment Campaigns¶
The most powerful capability is mixed-environment campaigns (rl-mixed-v1). One live batch can contain shell + browser + orchestrator episodes. The campaign controller:
- Samples tasks across environments in balanced ratios.
- Runs episodes concurrently.
- Aggregates rewards and comparison outcomes.
- Makes one rollback decision for the entire student — not per-environment.
This means shell bugfix episodes and orchestrator dispatch decisions can both improve the same student policy. The shared reward signal is "does this help the agent succeed at the end-to-end task?"
Training Phases¶
- Phase 1 (V1): Synthetic shell bugfix tasks with teacher shaping. Reproducible, fast iteration.
- Phase 2: Real shell repository tasks. Same student, harder distribution.
- Phase 3: Online monitoring + promotion. Rollback-protected live updates.
- Phase B: Browser adapter — controlled real web flows (auth walls, form submissions, scroll patterns).
- Phase C: Orchestrator adapter — high-value control decisions (preflight gating, dispatch routing, quality signals).
- Phase D/E: Mixed-environment validation — all three environments together.
What This Unlocks¶
With a shared student policy across environments, we can:
- Improve dispatch routing by training on orchestrator decisions: which tasks should go to subagent vs. dry-run vs. human gate?
- Reduce false positives in clarity-gate by training on blocked-checkpoint episodes: what does a genuine "needs human" signal look like vs. noise?
- Sharpen browser automation by training on web interaction patterns: what click sequences reliably complete auth, form submission, or content creation?
- Cross-pollinate learnings: shell RL improvements on error recovery also help browser tasks that hit errors.
How to Run¶
# Shell RL: benchmark generation -> training -> evaluation
node scripts/rl-shell-v1.mjs benchmark-generate --count 20
node scripts/rl-shell-v1.mjs train --epochs 5
node scripts/rl-shell-v1.mjs eval
# Mixed-environment campaign
node scripts/rl-mixed-v1.mjs mixed --browser-only
node scripts/rl-mixed-v1.mjs mixed --orchestrator-only
node scripts/rl-mixed-v1.mjs mixed --mixed
# Evaluate mixed campaign
node scripts/rl-mixed-v1.mjs mixed-eval
Current Status¶
- RL Core: stable — all shared contracts validated, 40+ tests passing
- Shell RL V1: stable — Phase 1 + 2 implemented, Phase 3 online monitoring in progress
- Browser RL V1: beta — adapter + eval harness implemented
- Orchestrator RL V1: beta — adapter + eval harness implemented
- Mixed-environment campaigns: experimental — end-to-end validated on held-out tasks
The next milestone is Phase D/E validation: confirming that mixed-environment training produces a student that outperforms single-environment training on held-out tasks across all three environments.