AIOS RL Training System: 合成バグ修正からマルチ環境学習へ¶
aios orchestrate のライブ実行を出して以来、私たちはその下にあるもっと深い仕組みを作ってきました。shell、ブラウザ、オーケストレーターのタスクを横断して 1 つの student ポリシーを継続的に改善する マルチ環境強化学習(RL)システムです。すべての環境は、統一された学習コントロールプレーンを共有します。
この投稿では、何を作ったのか、なぜその形にしたのか、そして何が可能になるのかを説明します。

環境ごとの RL を作ると何が問題か¶
RL 以前、システムにあった "student" は暗黙の行動事前分布でした。スキルのプロンプト、ディスパッチポリシー、harness のヒューリスティクスに埋め込まれ、機能追加のたびに手で調整していました。「デモで動く」から「本番で安定する」までが長く、手作業になりがちです。
自然な次の一手は強化学習ですが、すぐにこう気付きます。
shell RL、browser RL、orchestrator RL をそれぞれコピペして別々に育てると、似ているが互換性のない 3 つの RL 実装になります。そうなると:
- ロールバック語義が分岐する
- リプレイのルーティングが比較不能になる
- チェックポイントの lineage が環境ごとに分断される(システム全体で比較できない)
- teacher/judge の統合レイヤが環境別に増殖して合成できなくなる
- デバッグが「なぜ browser RL だけ違う?」に支配される
正しい設計は 共有コントロールプレーンを先に抽出し、環境をそこへ差し込むことでした。
アーキテクチャ:1 つのコア、3 つの環境¶
scripts/lib/rl-core/ <- 共有コントロールプレーン
├── campaign-controller.mjs <- 収集/監視 epoch のオーケストレーション
├── checkpoint-registry.mjs <- active / pre_update_ref / last_stable lineage
├── comparison-engine.mjs <- better / same / worse / comparison_failed
├── control-state-store.mjs <- 再起動に強い制御スナップショット
├── epoch-ledger.mjs <- epoch 状態 + 劣化連続の追跡
├── replay-pool.mjs <- 4 レーンのルーティング(positive/neutral/negative/diagnostic)
├── reward-engine.mjs <- 環境 reward + teacher shaping の融合
├── teacher-gateway.mjs <- teacher 出力の正規化(Codex/Claude/Gemini/opencode)
├── schema.mjs <- 共有契約をここで検証
└── trainer.mjs <- PPO エントリ(online + offline)
scripts/lib/rl-shell-v1/ <- Shell 環境(合成バグ修正タスク)
scripts/lib/rl-browser-v1/ <- Browser 環境(制御された実 Web フロー)
scripts/lib/rl-orchestrator-v1/ <- Orchestrator 環境(制御判断)
scripts/lib/rl-mixed-v1/ <- マルチ環境キャンペーン
RL Core は共通の学習コントロールプレーンを所有します。エピソード契約、バッチ、比較、劣化追跡、チェックポイント lineage、ロールバック規則、リプレイのルーティング、trainer のエントリポイントを定義します。
環境アダプタは「実行に依存する部分」だけを持ちます。タスクサンプリング、エピソード実行、証拠収集、環境固有の検証入力。它们実装一个薄薄的适配器接口 — RL ロジックは RL Core に漏らしません。
共有エピソード契約¶
shell / browser / orchestrator のどのエピソードも同じ構造で出力します。
Episode {
episodeId: string;
environment: 'shell' | 'browser' | 'orchestrator';
taskId: string;
trajectory: TrajectoryStep[]; // 行動 + 観測
outcome: 'success' | 'partial' | 'failure' | 'blocked';
reward: number;
teacherSignal?: TeacherSignal; // 失敗や境界事例で付与
comparison?: ComparisonResult; // 前ポリシーとの比較
}
この統一があるから、環境を跨いだ比較・リプレイが意味を持ちます。
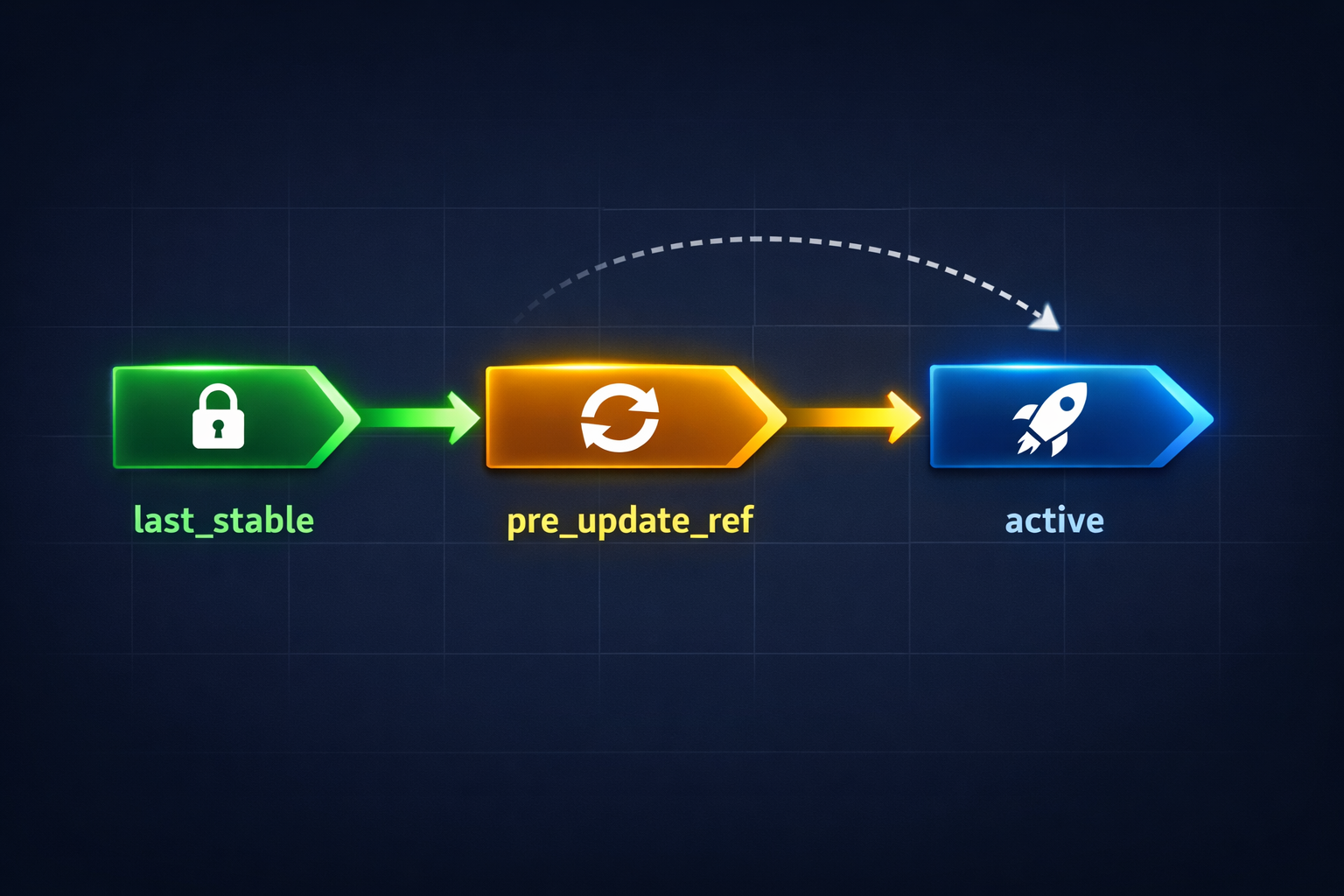
チェックポイント lineage:3 ポインタモデル¶
active ────────────── 現在利用中のポリシー
│
├── pre_update_ref ── 直前更新前のスナップショット(ロールバック先)
│
└── last_stable ───── 比較で安定が確認された直近のポリシー
- PPO 更新ごとに新しい
activeを生成 - 更新前の
activeはpre_update_refに退避 - 次の比較で劣化が出たら
pre_update_refにロールバック - 安定比較が積み上がると
activeをlast_stableに昇格
オンライン学習を実用にするための「安全な探索 + 自動ロールバック」です。
リプレイプール:4 レーン¶
全エピソードを貯めるのではなく、比較結果に基づき決定的にレーン分けします。
| レーン | 条件 | 用途 |
|---|---|---|
positive |
以前より改善 | PPO + distillation |
neutral |
同等 | 多様性サンプリング |
negative |
悪化 | KL 正則化のターゲット |
diagnostic_only |
teacher が判断した境界ケース | 解析(学習には使わない) |
学習済みルータではなく、比較結果で決めるのでデバッグが容易です。

マルチ環境キャンペーン¶
もっとも強力なのは rl-mixed-v1 による マルチ環境キャンペーンです。1 つのライブバッチに shell + browser + orchestrator のエピソードを混在させられます。キャンペーンコントローラは:
- 環境比率を保ってタスクをサンプル
- エピソードを並行実行
- reward と比較結果を集約
- student 全体に対して 1 回のロールバック判断(環境ごとではない)
つまり shell のバグ修正も、orchestrator の制御判断も、同じ student を改善します。評価は「エンドツーエンドで成功確率が上がるか」です。
トレーニングフェーズ¶
- Phase 1 (V1): teacher shaping を使った合成 shell バグ修正(再現性が高い)
- Phase 2: 実リポジトリの shell タスク(同じ student で分布を広げる)
- Phase 3: オンライン監視 + promotion(ロールバック保護付き)
- Phase B: browser アダプタ(認証壁/フォーム/スクロールなど制御フロー)
- Phase C: orchestrator アダプタ(preflight/dispatch/quality など高信号の制御判断)
- Phase D/E: マルチ環境統合検証(3 環境まとめて)
何が可能になるか¶
共有 student により、次が現実的になります。
- dispatch ルーティングの改善: orchestrator の制御判断として「どの作業を subagent に振るか、dry-run にするか、人間ゲートにするか」を学習できる
- clarity-gate の誤検知低減: blocked-checkpoint のエピソードから「本当に needs human の信号か、ノイズか」を学習できる
- ブラウザ自動化の精度向上: 認証、フォーム送信、スクロールなどの実 Web パターンから学習できる
- 環境間の学習共有: shell のエラー回復が browser のエラー回復にも効く(student が共通だから)
実行方法¶
# Shell RL: benchmark generation -> training -> evaluation
node scripts/rl-shell-v1.mjs benchmark-generate --count 20
node scripts/rl-shell-v1.mjs train --epochs 5
node scripts/rl-shell-v1.mjs eval
# Mixed-environment campaign
node scripts/rl-mixed-v1.mjs mixed --browser-only
node scripts/rl-mixed-v1.mjs mixed --orchestrator-only
node scripts/rl-mixed-v1.mjs mixed --mixed
# Evaluate mixed campaign
node scripts/rl-mixed-v1.mjs mixed-eval
現在の状態¶
- RL Core: stable — 共有契約が検証され、テストが通過
- Shell RL V1: stable — Phase 1 + 2 実装済み、Phase 3 は進行中
- Browser RL V1: beta — adapter + eval harness 実装済み
- Orchestrator RL V1: beta — adapter + eval harness 実装済み
- Mixed-environment campaigns: experimental — ホールドアウトタスクで end-to-end 検証済み
次のマイルストーンは Phase D/E 検証です。マルチ環境学習が単一環境学習よりも、3 環境のホールドアウトタスクで上回ることを確認します。